Accelerating CUDA: Vector Sum Kernel Optimization
This blog will take you through my journey of Cuda VectorSum kernel optimization. I started working on this as part of the GPU-Mode competition on CUDA kernel optimization. This is the first kernel I have ever written and optimized (so don’t be surprised if i seem naive :) I did this cuz i wanted to get into parallel programming and work on something where I could truly apply my theoretical knowledge to code that works..
VectorSum is a fundamental operation that is used in Large-Language-Models (Loss Function calc, Activation Layers, Gradient Aggregation, Embedding Layers) , and many other frameworks. I want you to join me on this optimization journey, where I’ll explain each optimization strategy and also show how other approaches didn’t work as expected. Trial and error, huh…
Level 1 : basic-intuition
The most basic vector sum implementation for an input array of N elements (i.e., summing all elements of a single array into a scalar) is a single-threaded kernel that iterates through the entire array sequentially. This is the simplest way to compute a sum, but it completely ignores parallelism.
__global__ void vector_sum_naive(const float *A, float *sum, int N) {
float temp = 0.0f;
for (int i = 0; i < N; ++i) {
temp += A[i]; // Sequential summation
}
*sum = temp; // Store result in global memory
}
Problem in this approach :
No parallelism: Uses only one thread instead of leveraging CUDA's parallel execution.
Extremely slow: Loops sequentially over N elements, wasting GPU resources.
Poor memory access: Every access goes to global memory, which is slow.
Level 2 : Memory Coalescing
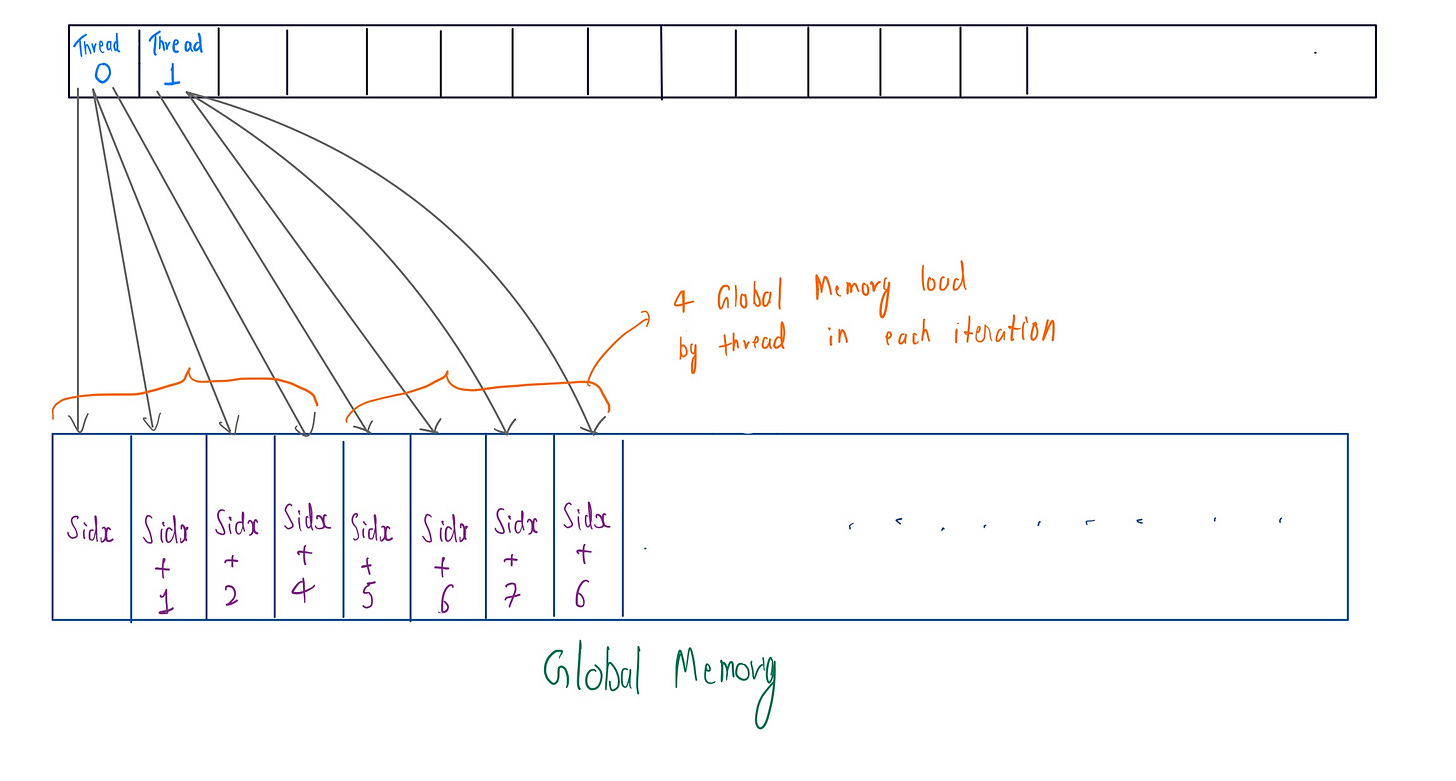
To optimize global memory access coalescing for the VectorSum, we need to ensure that consecutive threads in a warp (warp consist of 32 threads with contigiugous threadIdx values executing in parallel. It is the fundamental parallel unit ) access consecutive memory locations. This allows the GPU to group memory transactions efficiently, reducing the number of global memory accesses overall.
Global memory resides in the device(GPU) and is accessed via 32, 64, or 128-byte memory transactions. So if we execute a warp of size 32 (default ) and its threads access consecutive memory addresses, we can group those in (32, 64, or 128) byte memory transaction .
const int tid = threadIdx.x;
const int bid = blockIdx.x;
const int globalIdx = bid * blockDim.x + tid;
// grid-stride loop for memory coalescing
for (int i = globalIdx; i < N; i += gridDim.x * blockDim.x) {
threadSum += input[i];
}
The code above shows the grid-stride loop for accessing the elements from the global memory in memory coalesced way. While executing warp each thread, in each iteration is accessing a contiguous memory location. So, if we are accessing float(4 byte) then all 32 threads can be grouped into a single 128 byte transaction.
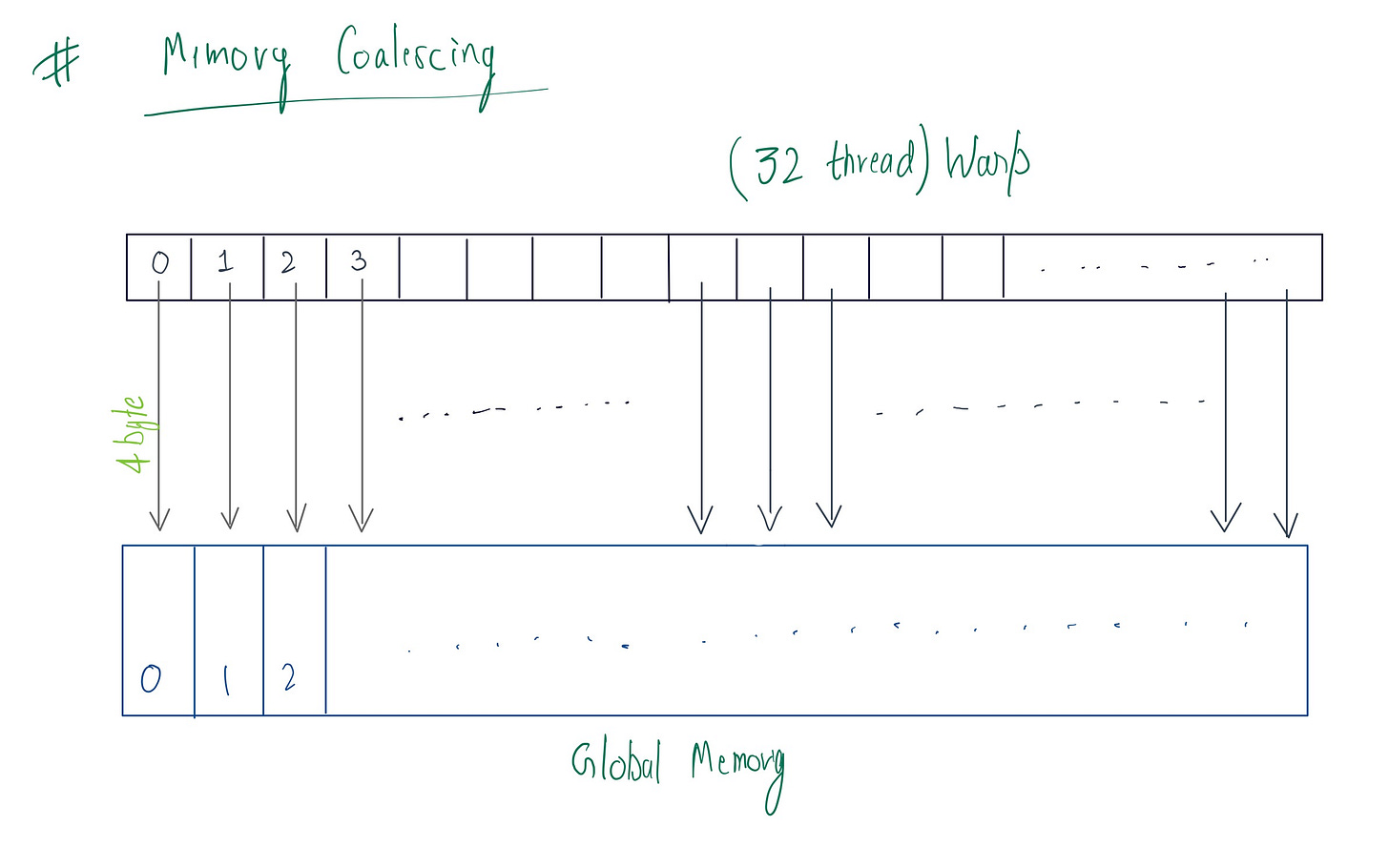
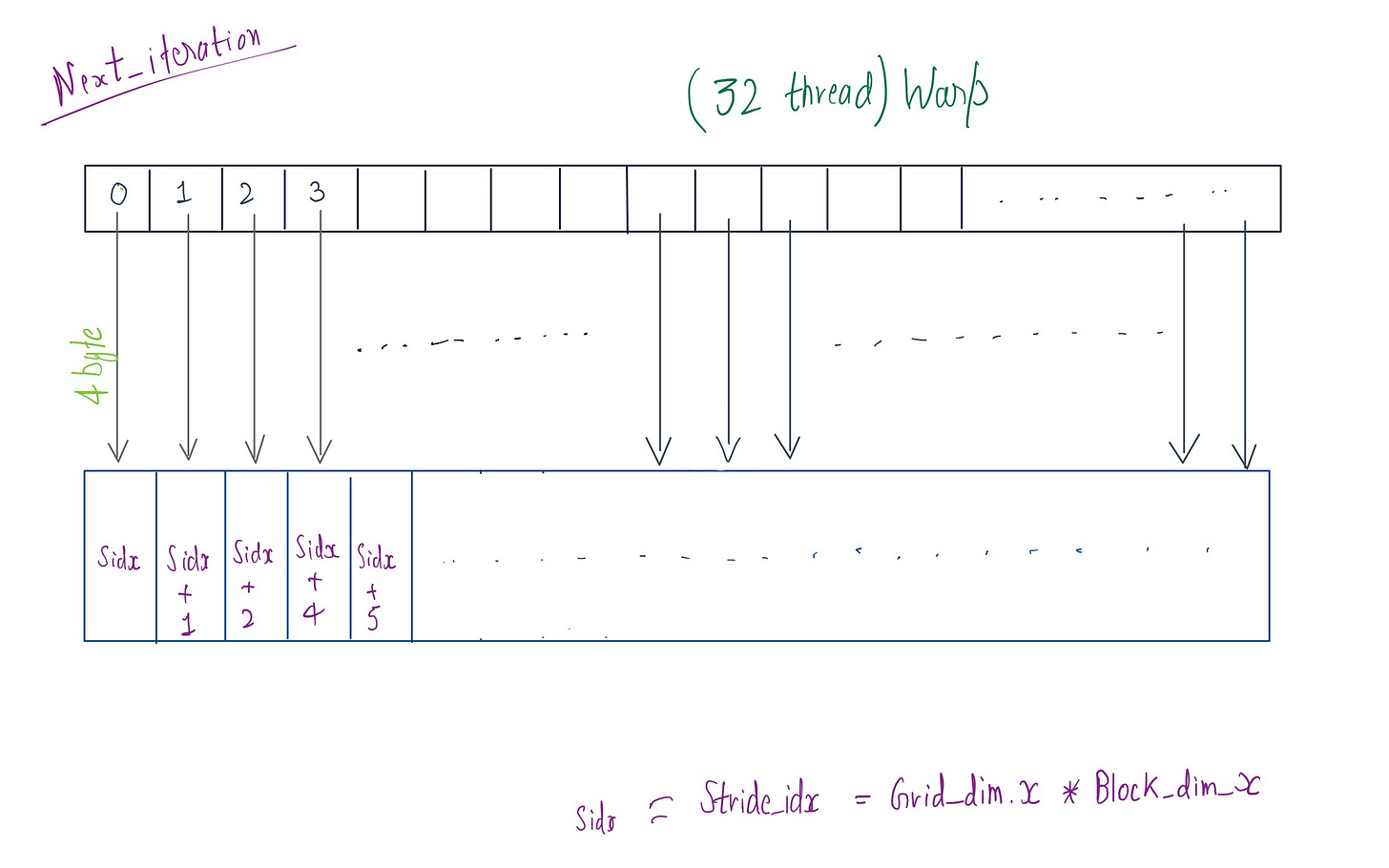
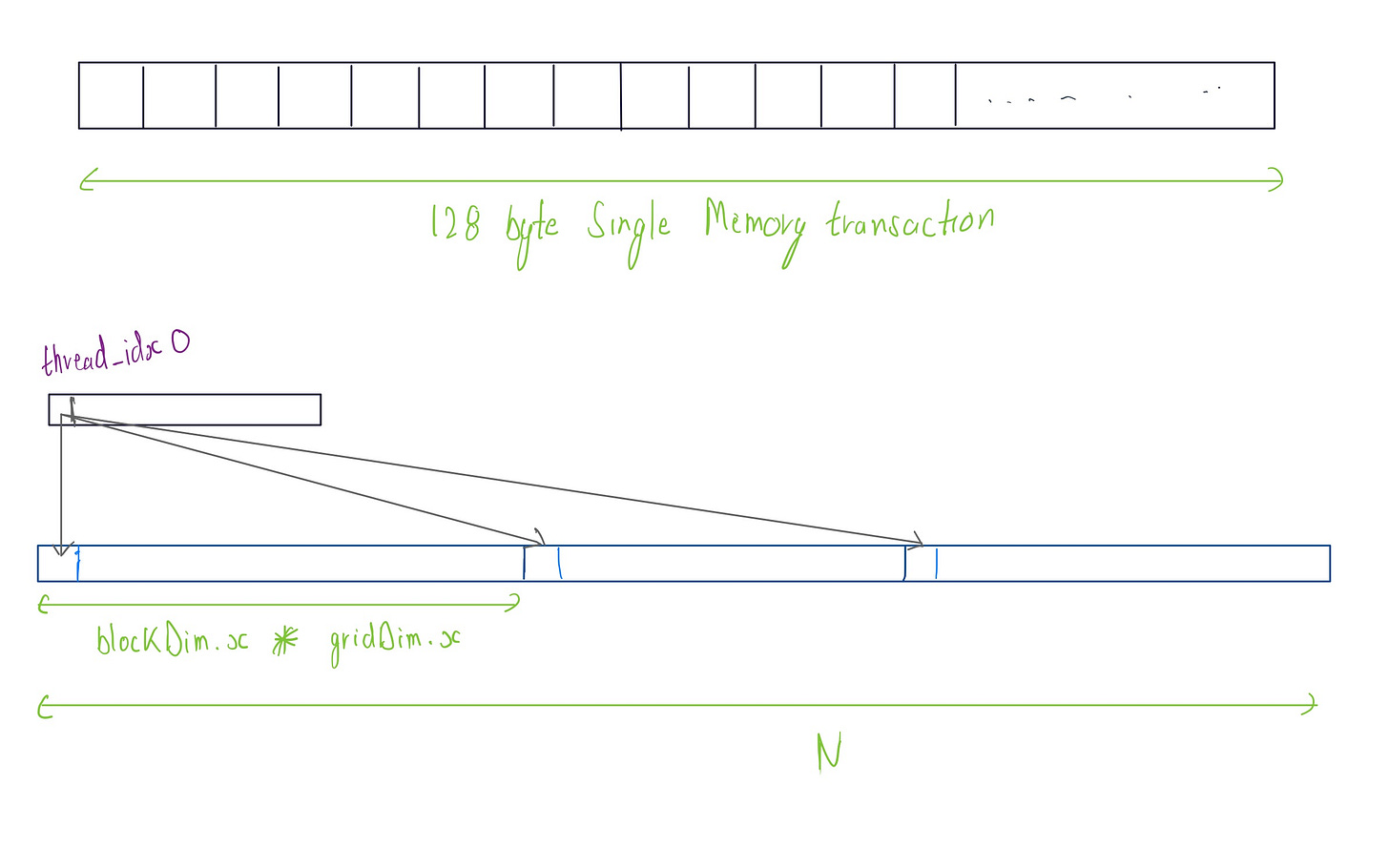
But there is a catch: if the stride is not multiple of 32 , it can lead to misaligned memory access, resulting in inefficient memory access and wasted bandwidth , as the GPU will have to issue multiple memory transactions.
Level 3 : Reduction tree and Control divergence
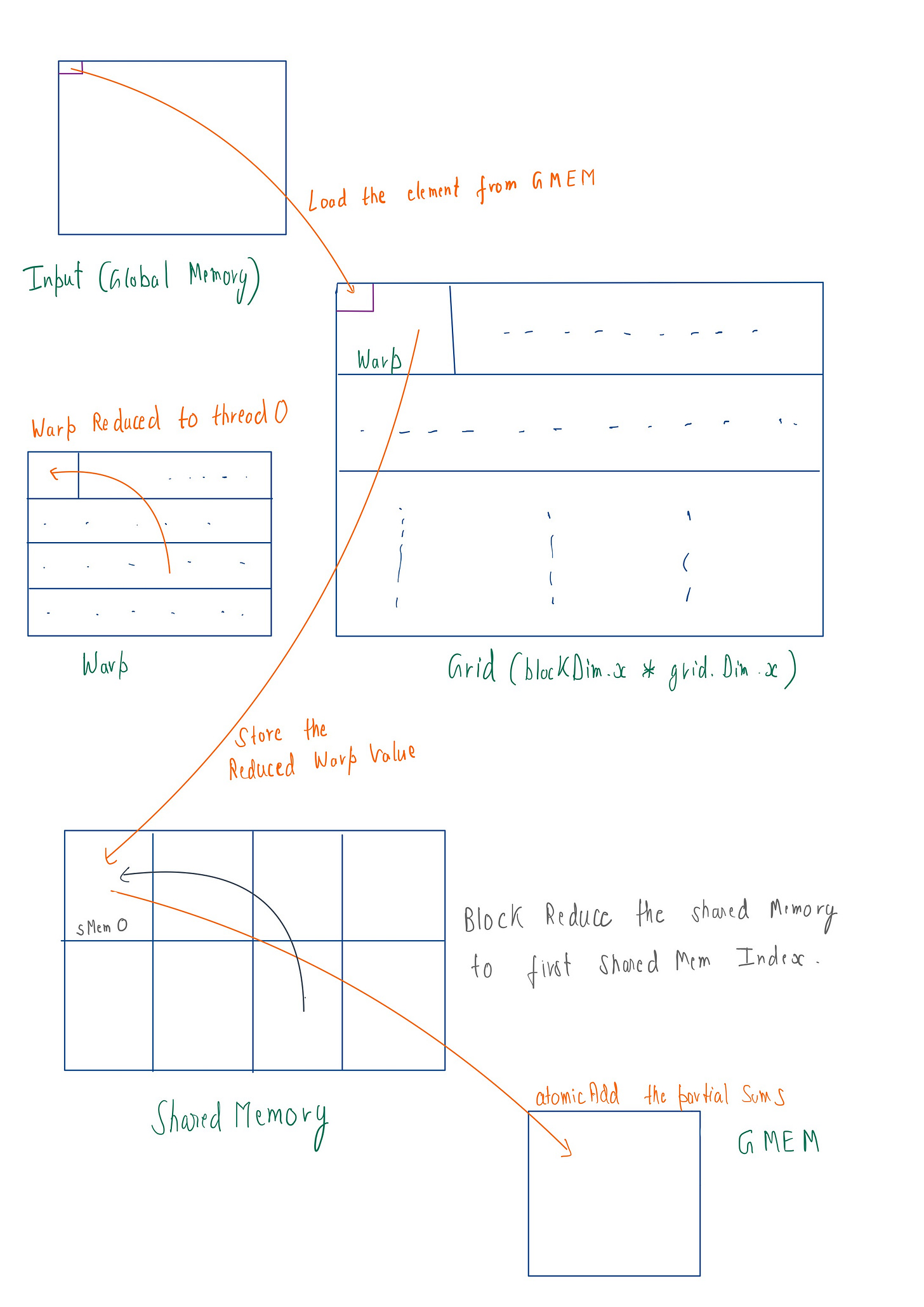
After summing values from global memory efficiently per thread, we now want to add these thread values in optimized manner . A reduction tree can be very useful here, as it treats thread values as 32 leaves (one warp) and perform pairwise summing each iteration . The final value is reduced to the first thread's index value.
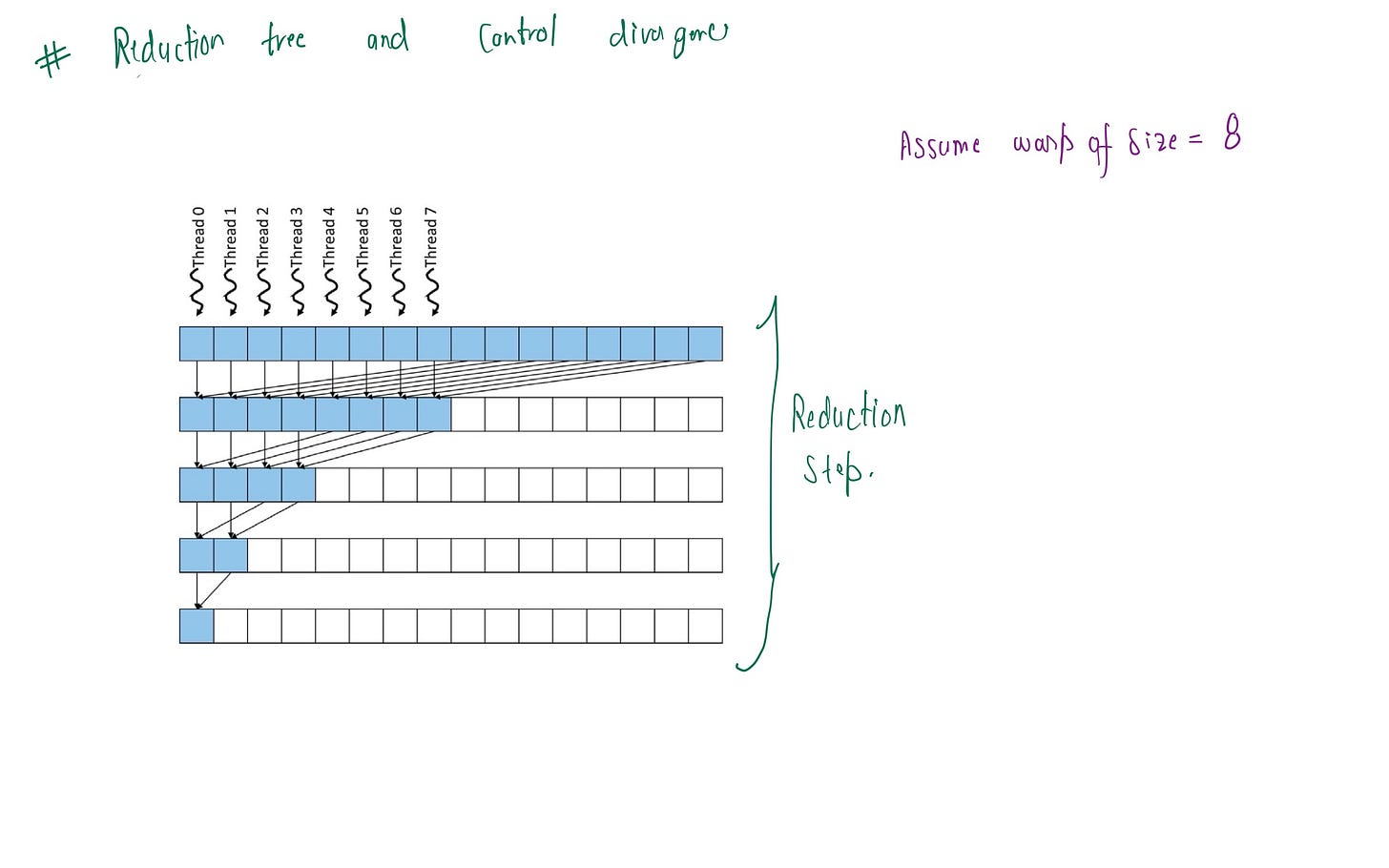
For warpSize of 32 shown below
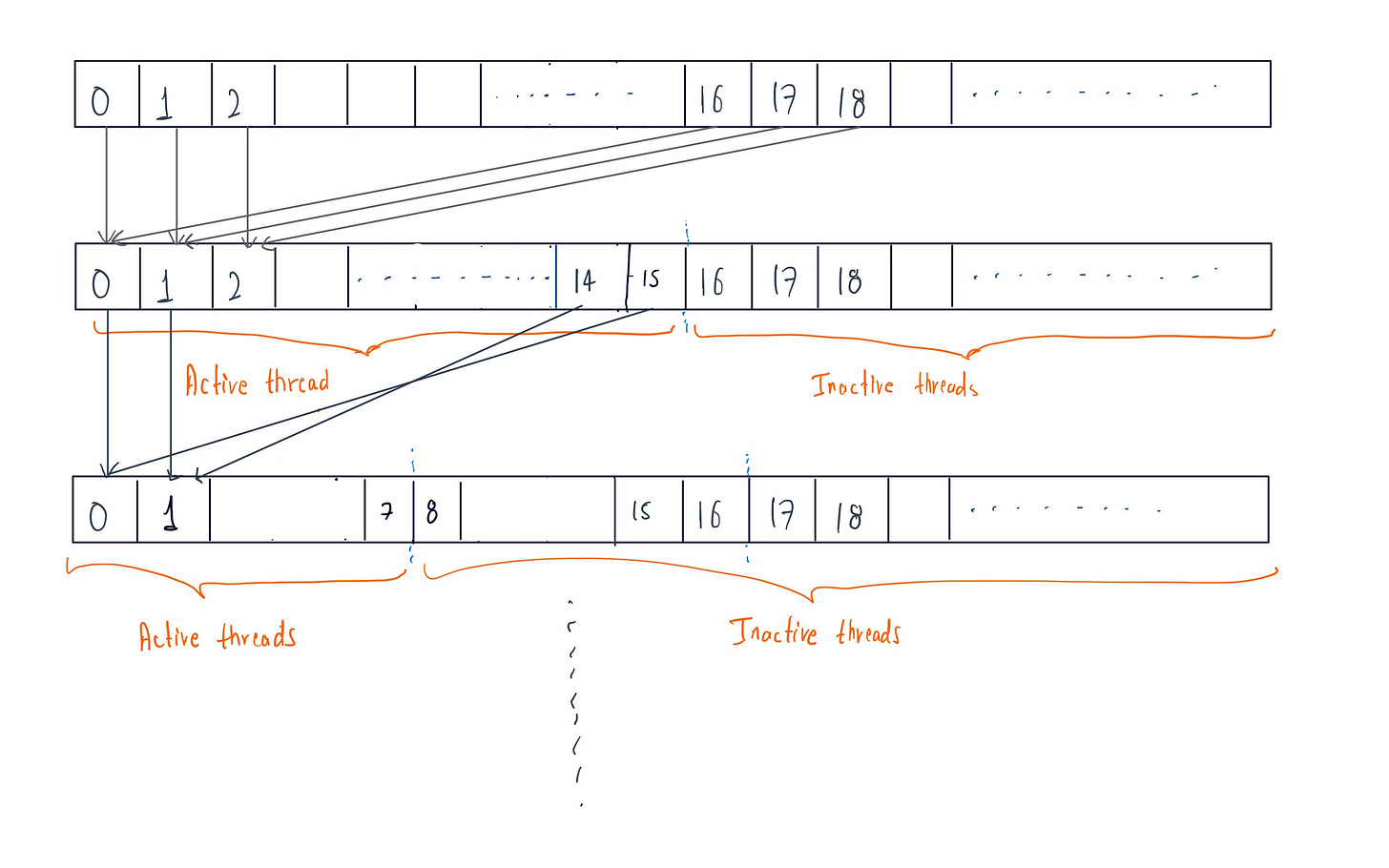
Control divergence can be minimized by dividing the warp into two set of groups for pairwise reduction at each iteration, rather than consecutive reduction. By doing so, we insure that contiguous active threads are maintained at each iteration . This maximizes execution resource utilization for computation, reducing wasted cycles caused by inactive threads within a warp
__inline__ __device__ scalar_t warpReduceSum(scalar_t val) {
for (int offset = 16; offset > 0; offset /= 2) {
val += __shfl_down_sync(0xffffffff, val, offset);
}
return val;
}
In the code, we shift the thread register values by offset of (16, 8,4,2,1) meaning the thread values are not shifted consecutively. Instead, in a warp of size 32 , threadIdx 16 is shifted to thread_idx 0 , threadIdx 17 to threadIdx 1 and so on. This pattern continues for all 5 iterations. We shift the register value using __shfl_down_sync(0xffffffff, val, offset) which transfers the value from one thread's register to another within the same warp (to be noted) . In this way, we achieve the tree reduction with control divergence . I also tried unroll loop but didn’t get any improvements.
In __shfl_down_sync , 0xffffffff is a hexadecimal mask that instructs the compiler to perform the shift operation on all of 32 threads of warp.
Level 4: Shared cache Memory
In modern GPUs( i am using L4 GPU) there are two two levels of memory. One is the global memory I mentioned earlier, and the other is L2 cache or Shared Memory (SMEM). The primary reason for using SMEM is purely speed :SMEM has a bandwidth of 1.3–1.5 TB/s with a latency of ~20–30 cycles, while GMEM has a bandwidth of 300 GB/s with a latency of 400–600 cycles. As we can see, there is many Xed(times) difference.
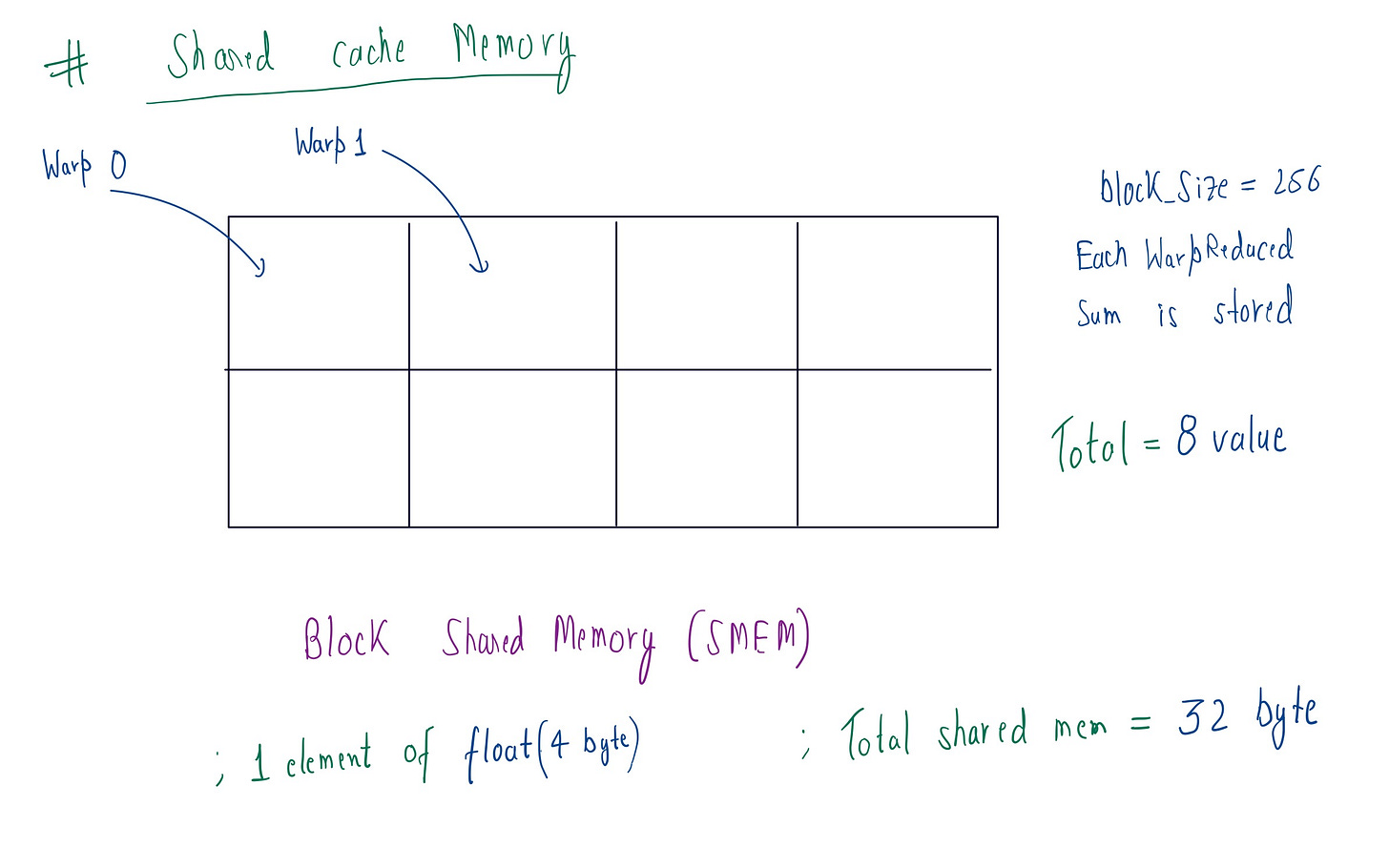
My GPU has a total of 48 MB of SMEM, which is shared among all the SMs (stream multiprocessors ) . If I take the numBlock=4096 , then the each block gets 12,288 bytes (48 * 1024 * 1024 / 4096) . Thus, the reduced warp sum we calculated earlier is stored in each block’s SMEM . For blockSize=256 , after warp reduction, we need to store 8 elements (256 / 32) per block . Then for storing a float(4byte) val we need to allocate 32byte (8 * 4) of memory per block .
// Store warp sums to shared memory
if (tid % 32 == 0) {
sharedMem[tid / 32] = threadSum;
}
As you can see above code, the thread with the threadIdx that is a multiple of 32 stores its value in shared memory (cuz after every warp reduction, all 32 thread values are stored in first thread’s index) .
We are storing the values in block’s SMEM so that we can later perform BlockSumReduce just like we did with warpReduce. You'll see this shortly below.
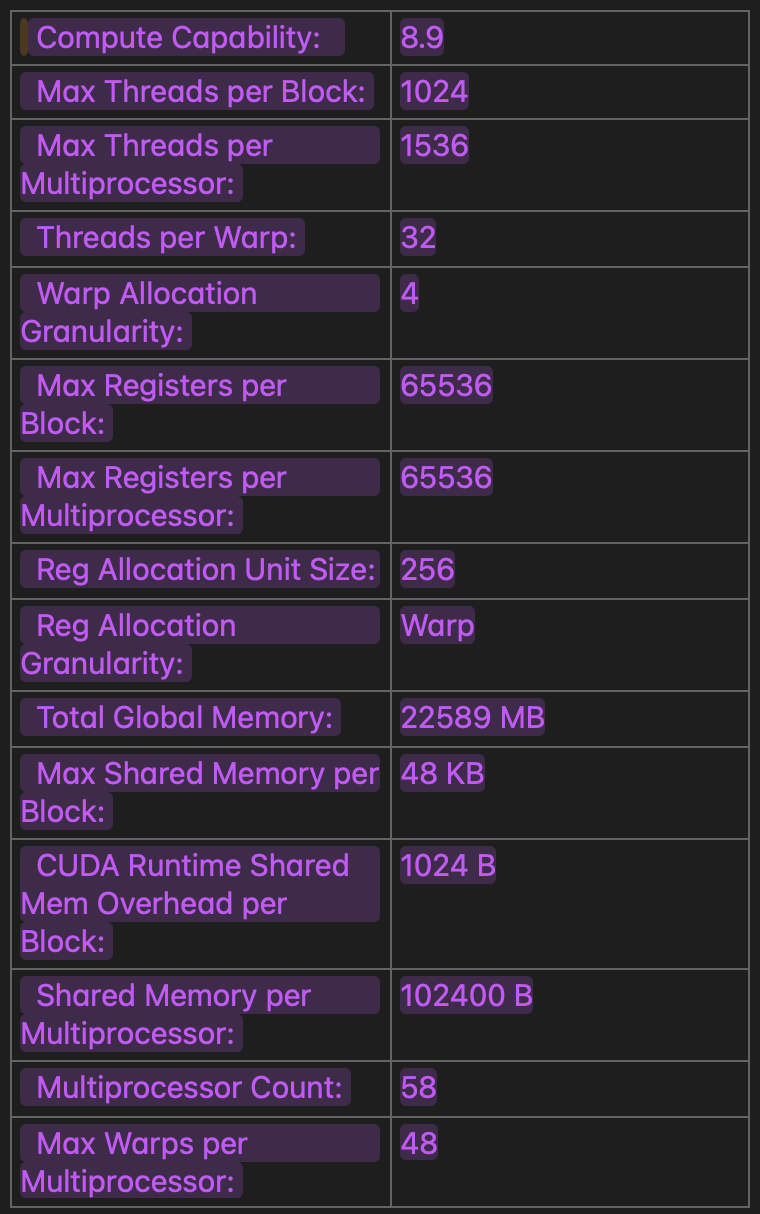
Occupancy Calculation for the the kernel
I am using L4 GPU , here are the its stats which i get by using cudaGetDeviceProperties api .
Resource demands for the kernel :
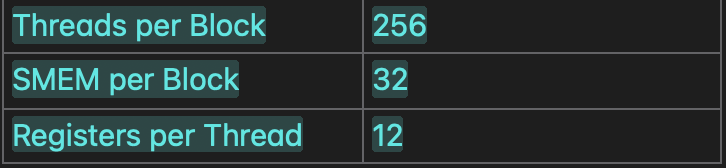
Here we need to find out the occupancy of the kernel , so will do a calculation about how much load is there on each SM(stream multiprocessor) . As work is scheduled in SM based on block granularity.
Threads: 256 threads per block & max 1536 threads per SM ~ at max 6 blocks
Shared memory: 32B/block + 1024B/block (cuda runtime overhead) = (102400B per SM) / (1056B per Block) ~~ 96 blocks approx.
Registers: 12 register thread * 32 threads per warp = 384 regs per warp. Register scheduled granularity is 256 regs per warp , now if we round to (nearest)512 regs per warp. We have (256 threads per block / 32) = 8 warps per block, hence 512 regs per warp * 8 warps per block = 4096 regs per block. Max 65536 regs per SM , so (4096 reg per block * 6 = 24576) 24576 reg per SM , max is 6 blocks
Limiting factor (bottleneck):
Active Blocks per SM = min(
Blocks per SM (SMEM),
Blocks per SM (Threads),
Blocks per SM (Registers)
) = 6 blocks per SM
Therefore max active warp will be (6 blocks per SM * 8 warp per block) = 48
And Occupancy be (Active Warps per SM / 48) × 100% = 100%
Overall occupancy of GPU:
There are total 58 SMs in L4 GPU , and executing at max 48 Warps per SMs. According to that for full GPU occupancy :
Total warps = (58 * 48) 2,784 warps Total threads = (2784 * 32) 89,088 threads Based on block_size = 256 Min no. of Blocks in total = (89,088 / 256) 348 blocks
I am taking the block size of 4096 , after trying other values .
const int numBlocks = min((N + blockSize - 1) / blockSize, 4096);
Arithmetic Intensity and Thread coarsening
Arithmetic intensity gives us an idea of whether kernel is memory or compute bound . Thread coarsening refers to combining the work of multiple threads into fewer threads, increasing the computational load per thread. Fewer threads means fewer redundant memory access, but increased register occupancy .
Now lets find out the arithmetic intensity of kernel for further optimization :
For N = 4096, blockDim = 256 (16 adds/thread):
1. Grid-Stride Loop (Element Adds)
Per Thread: 16 adds (4096 / 256)
Total FLOPs: 256 threads * 16 adds = 4096 FLOPs
2. Warp-Level Reduction (5 Steps per Thread)
Per Warp: 32 threads * 5 adds = 160 FLOPs
Total Warps: 256 threads / 32 = 8 warps
Total FLOPs: 8 warps * 160 FLOPs = 1280 FLOPs
3. Block-Level Reduction (5 Steps per Thread)
Active Threads: Only 1 warp (32 threads) reduces 8 partial sums.
Mask inactive threads: 8 threads participate
3 steps (offsets 4, 2, 1)
FLOPs: 8 threads * 3 adds = 24 FLOPs
Total FLOPs
= 4096 (element adds) + 1280 (warp reduction) + 24 (block reduction)
= 5400 FLOPs
Bytes Transferred
Global Memory:
- 4096 elements * 4B = 16,384 B
Shared Memory:
8 warp sums * 4B = 32 B (written)
8 warp sums * 4B = 32 B (read by final warp)
Total: 64 B
Atomic Add:
1 * 4B = 4 B per block
If no. of blocks is 1024
1024*4 = 4096 B
Total Bytes = 16,384 + 64 + 4096 = 20,544 B
Arithmetic Intensity (AI)
AI = Total FLOPs / Total Bytes = 5400 / 20,544 ≈ 0.26 FLOP/Byte
Based on the above analysis, we see that kernel is memory-bound. To optimize performance, we should increase computation and reduce memory operations (load/store).
Vectorized Loads from GMEM
Based on the concept that we understood above, we will apply vectorized loads of element from global memory . Here we are using float4 to load 4 input values, each of 4bytes each (16 bytes total) at each iteration of thread by reinterpret_cast the input. This increases FLOPs/Byte ratio , so even with identical memory traffic, vectorization quadruples FLOPs, improving Arithmetic intensity . It also hides latency with fewer loop iterations , more arithmetic ops between memory accesses.
While applying this we need to keep in mind a few things though. First, the input must be 16-byte aligned (use cudaMalloc) ,
cudaMalloc(&input, N * sizeof(float), 16)
Second we need to handle the remaining threads. If the remainder of (N / 4 != 0) is not zero , then we should add a check loop.
int remainder_start = (N / 4) * 4;
for (int i = remainder_start + globalIdx; i < N; i += total_threads) {
threadSum += input[i];
}
Whole code looks like below:
const int globalIdx = bid * blockDim.x + tid;
const int total_threads = blockDim.x * gridDim.x;
scalar_t threadSum = 0;
// Vectorized loads
using Vec4 = float4;
const Vec4* vec_input = reinterpret_cast<const Vec4*>(input);
for (int i = globalIdx; i < N/4; i += total_threads) {
Vec4 v = vec_input[i];
threadSum += v.x + v.y + v.z + v.w;
}
// Handle remainder
int remainder_start = (N / 4) * 4;
for (int i = remainder_start + globalIdx; i < N; i += total_threads)
{
threadSum += input[i];
}
Now, let’s check if this vectorized load is memory coalesced or not. Although in each iteration of a thread there is 16-byte memory transaction , 8 such threads from the warp could be coalesced into a single 128-byte memory transaction.
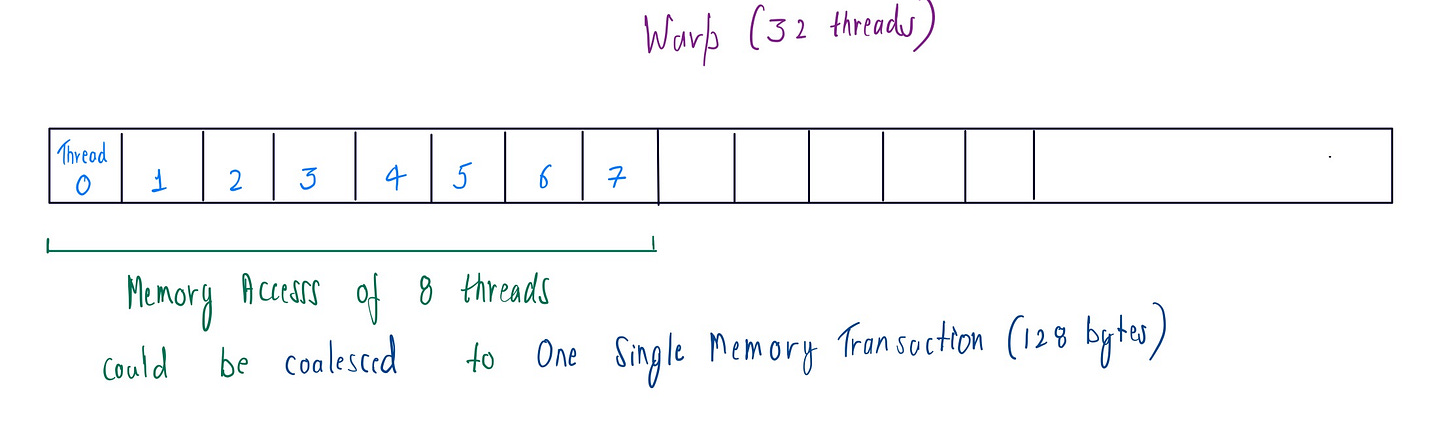
After benchmarking , we find that we don’t get much improvement with this .
Vectorized Loads from SMEM
I have tried to brainstorm and explored many approaches , but none seem to be able to do vectorized load of SMEM for my given code .
// Shared memory for block-level reduction
extern __shared__ __align__(sizeof(scalar_t)) char shared_mem_char[];
scalar_t* sharedMem = reinterpret_cast<scalar_t*>(shared_mem_char);
// cast it to 128bit load
loat4* sharedMemVec = reinterpret_cast<float4*>(sharedMem);
From our approach, we want to load the warpReduced value into shared memory. However, even if we reinterpret_cast the scalar_t to
Level 5 : atomicAdd partial_sums
After trying two-pass-kernel we don’t get the result as expected . Cuz in that approach we have to first write the partial_sum of each block to global buffer memory and then load it back in the second kernel in the same way as first one.
// First warp reduces partial sums
if (tid < 32) {
scalar_t val = (tid < (blockDim.x + 31) / 32) ? sharedMem[tid] : 0;
scalar_t blockSum = warpReduceSum(val);
// final reduced partial sum is added to global me via atomicAdd
if (tid == 0) {
atomicAdd(output, blockSum);
}
}
In atomicAdd() it is used to add a val to target address, which can be in global or shared memory (but not for a warp), while maintaining atomicity without race conditions. However, there might be problem in this approach : when the first warp executes this ops , other have to wait for it to finish . So, its generally recommended not to use it for very large block_size , as it will cause delays.
Though this is the best approach i have found so far after benchmarking against other methods.
Loop unrolling
I have tried to unroll the the grid-stride loop :
#pragma unroll 4
for (int i = globalIdx; i < N; i += gridDim.x * blockDim.x) { threadSum += input[i]; }
I tried #pragma unroll 4 to the unroll the loop by taking 4 input sequences at once. If out-of-memory errors are a concern when the input size N is not a multiple of 4, manual unrolling can be used instead.
for (int i = globalIdx*4 ; i < limit; i += gridDim.x * blockDim.x) {
if(i < N) threadSum += input[i];
if(i+1 < N) threadSum += input[i+1];
if(i+2 < N) threadSum += input[i+2];
if(i+3 < N) threadSum += input[i+3];
}
However, after benchmarking, there was no positive improvement from using it :(
Two-pass-kernel-reduction
The intuition behind this was that in the first pass, we get results from each blocks . These result could be stored in output buffer (still using GMEM) . Then, a final reduction kernel with grid_size=1 (no. of blocks) and block_size=256 would allow us to perform BlockReduce on the outputs of each block .
__inline__ __device__ scalar_t blockReduceSum(scalar_t val) {
// as 256 threads per block (256/32=8) 8 elements to store in share mem
static __shared__ scalar_t shared[8];
// id of thread within warp
int lane = threadIdx.x % 32;
// warp id
int wid = threadIdx.x / 32;
val = warpReduceSum(val);
if (lane == 0) shared[wid] = val;
__syncthreads();
val = (threadIdx.x < (blockDim.x + 31)/32) ? shared[lane] : 0;
if (wid == 0) val = warpReduceSum(val);
return val;
}
__global__ void final_reduce_kernel(
const scalar_t* __restrict__ block_sums,
scalar_t* __restrict__ output,
int num_blocks
) {
scalar_t sum = 0;
for (int i = threadIdx.x; i < num_blocks; i += blockDim.x) {
sum += block_sums[i];
}
sum = blockReduceSum(sum);
if (threadIdx.x == 0) {
output[0] = sum;
}
After benchmarking however, there was no improvement compared to atomicAdd() . In fact, the performance was even worse.
Conclusion
After trying all the technique and trick that i am aware of we finally arrive at the final code:
#include <cuda_runtime.h>
#include <iostream>
#include <vector>
#include <random>
#include <cmath>
#include <torch/extension.h>
// for benchmark
#include "task.h"
#include "utils.h"
// Warp-level reduction using shuffle instructions
template <typename scalar_t>
__inline__ __device__ scalar_t warpReduceSum(scalar_t val) {
for (int offset = 16; offset > 0; offset /= 2) {
val += __shfl_down_sync(0xffffffff, val, offset);
}
return val;
}
// Multi-level reduction kernel
template <typename scalar_t>
__global__ void vector_sum_kernel(
const scalar_t* __restrict__ input,
scalar_t* __restrict__ output,
const int N
) {
// Shared memory for block-level reduction
extern __shared__ __align__(sizeof(scalar_t)) char shared_mem_char[];
scalar_t* sharedMem = reinterpret_cast<scalar_t*>(shared_mem_char);
const int tid = threadIdx.x;
const int bid = blockIdx.x;
const int globalIdx = bid * blockDim.x + tid;
scalar_t threadSum = 0;
// grid-stride loop for memory coalescing
for (int i = globalIdx; i < N; i += gridDim.x * blockDim.x) {
threadSum += input[i];
}
// Warp-level reduction
threadSum = warpReduceSum(threadSum);
// Store warp sums to shared memory
if (tid % 32 == 0) {
sharedMem[tid / 32] = threadSum;
}
__syncthreads();
// First warp reduces partial sums
if (tid < 32) {
scalar_t val = (tid < (blockDim.x + 31) / 32) ? sharedMem[tid] : 0;
scalar_t blockSum = warpReduceSum(val);
// store the reduced partial sums per block in global memory via atomicAdd
if (tid == 0) {
atomicAdd(output, blockSum);
}
}
}
torch::Tensor vector_sum_cuda(torch::Tensor input) {
TORCH_CHECK(input.device().is_cuda(), "Input must be a CUDA tensor");
TORCH_CHECK(input.dim() == 1, "Input must be 1-dimensional");
const int N = input.numel();
if (N == 0) {
// Return a scalar tensor
return torch::zeros(1, torch::TensorOptions()
.dtype(torch::kFloat32)
.device(input.device()));
}
const int blockSize = 256;
const int numBlocks = min((N + blockSize - 1) / blockSize, 4096);
auto output = torch::zeros({1}, input.options());
// For very small inputs,
if (numBlocks == 1) {
dim3 grid(1);
dim3 block(blockSize);
AT_DISPATCH_FLOATING_TYPES(input.scalar_type(), "vector_sum_kernel", ([&] {
size_t shared_mem_size = (blockSize / 32) * sizeof(scalar_t);
vector_sum_kernel<scalar_t><<<grid, block, shared_mem_size>>>(
input.data_ptr<scalar_t>(),
output.data_ptr<scalar_t>(),
N
);
}));
}
else {
//
dim3 grid1(numBlocks);
dim3 block1(blockSize);
size_t shared_mem_size1 = (blockSize / 32) * sizeof(float);
AT_DISPATCH_FLOATING_TYPES(input.scalar_type(), "vector_sum_kernel", ([&] {
size_t shared_mem_size1 = (blockSize / 32) * sizeof(scalar_t);
vector_sum_kernel<scalar_t><<<grid1, block1, shared_mem_size1>>>(
input.data_ptr<scalar_t>(),
output.data_ptr<scalar_t>(),
N
);
}));
}
cudaError_t err = cudaGetLastError();
if (err != cudaSuccess) {
throw std::runtime_error(cudaGetErrorString(err));
}
// final output
return output;
Benchmark as compared to simple torch.sum()
Hats off to the PyTorch team they have truly optimized it exceptionally well...
Leaderboard benchmark :

Separate Benchmark of my code:
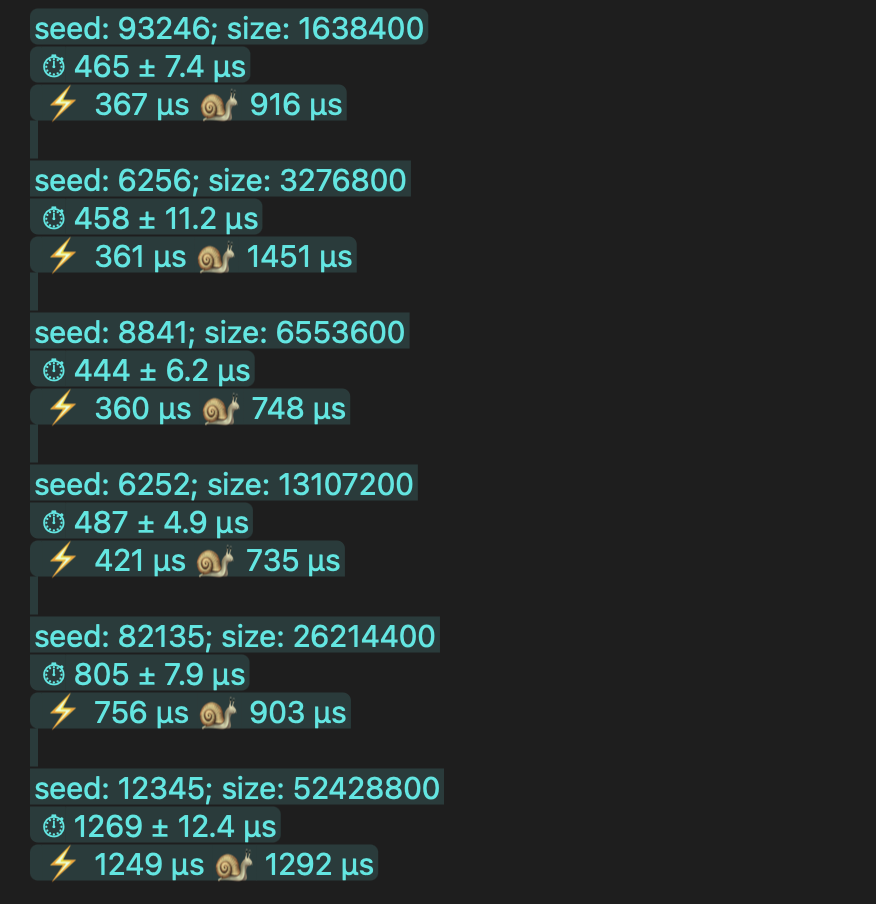
Note: benchmark score were taken form GPU mode Discord : discord.gg/gpumode
special credit :
I really want to thanks Simon Boehm as his blog really helped me structure my own blog. His goated work : https://siboehm.com/articles/22/CUDA-MMM,
And a special thanks to GPU-Mode as well for cultivating such a great community via Discord and for hosting these competitions! Discord link: discord.gg/gpumode
Github repo: https://github.com/sagar0x0/VectorSum-kernel